データベースドモデリングステップ
|
注記 |
|---|
|
このステップを使用するには、ASCMO-DYNAMICのライセンスが必要です。 |
Modelling ステップには以下のコンポーネントが含まれます:
Model table
各モデルの名前とモデリングメソッドが一覧表示されます。
モデリングメソッドを選択するには、Modelling Method 列のドロップダウンリストを使用します。
 Add Model
Add Model
モデルテーブルに新しいエントリを追加します。
Rename
別ウィンドウが開き、選択されているモデルの名前を変更することができます。
Delete Models
テーブル内で選択されているモデルをプロジェクトから削除します。テーブル内では、Ctrl/Shift による標準的な選択機能が使用
Export
モデルを各種フォーマットでエクスポートするためのコマンドが含まれます。
Matlab | モデルをMATLAB *.m ファイルにエクスポートします。 | ||
Python | モデルをPythonスクリプト(*.py)にエクスポートします。Pythonスクリプトへのモデルエクスポートを参照してください。 | ||
Simulink | モデルをSimulinkモデル(*.mdl または *.slx)にエクスポートします。Simulink®モデルへのモデルエクスポートを参照してください。
| ||
Simulink Script | モデルをMATLABスクリプト(*.m)にエクスポートし、これを使用してSimulinkモデルを生成することができます。Simulink®スクリプトへのモデルエクスポートを参照してください。
| ||
INCA/MDA | モデルをINCA/MDA用のPerlモジュール(*.pm)にエクスポートします。INCA/MDAへのモデルエクスポートを参照してください。 | ||
C Code | モデルをCコード(*.c)にエクスポートします。Cコードへのモデルエクスポートを参照してください。 | ||
GT-SUITE | モデルをGT-SUITE用のCコード(*.c)にエクスポートします。GT-SUITEへのモデルエクスポートを参照してください。 | ||
FMI | モデルを*.fmuファイルにエクスポートします。FMIへのモデルエクスポートを参照してください。 | ||
モデルをETAS Embedded AI Coder用のJSONファイルにエクスポートします。Embedded AI Coderへのモデルエクスポートを参照してください。 | |||
Bosch AMU | モデルをBosch AMU用ファイル(*.dcm、*.cdfx)にエクスポートします。 | ||
Bosch Flatbuffers | モデルをBosch Flatbuffers用ファイル(*.dcm)にエクスポートします(ファイル名:<output>_LSTM_Blobs)。エクスポートできるのは、モデリングメソッドがRNNで、セルタイプがLSTMセルである出力のみです。 |
モデルのプロパティを設定するには、テーブルからモデルを選択してモデリングメソッドを選択し、下のセクションで設定を行います。選択されているモデリングメソッドに応じて、異なるModel Propertiesを設定できます。
Inputs
1つ以上の入力を選択する必要があります。
モデルの入力を選択するには、Select Inputs ボタンをクリックします。
ウィンドウが開くので、リストから入力を選択し、OK で確定します。
テーブル内では、Ctrl/Shift による標準的な選択機能が使用
Output
1つの出力を選択する必要があります。
モデルの出力を選択するには、Select Output ボタンをクリックします。
ウィンドウが開くので、リストから出力を選択し、OK で確定します。
Training Datasets
1つ以上のトレーニングデータセットを選択する必要があります。
モデルのトレーニングデータセットを選択するには、Select Training Datasets ボタンをクリックします。
ウィンドウが開くので、リストからトレーニングデータセットを選択し、OK で確定します。
テーブル内では、Ctrl/Shift による標準的な選択機能が使用
Validation Datasets(オプション)
必要に応じて検証データセットを選択します。
モデルの検証データセットを選択するには、Select Validation Datasets ボタンをクリックします。
ウィンドウが開くので、リストから検証データセットを選択し、OK で確定します。
テーブル内では、Ctrl/Shift による標準的な選択機能が使用
検証データセットのリストを消去するには、Clear ボタンを使用します。
Model Type
使用したいモデルタイプを選択します。
モデルタイプとその設定の詳細についてはNARXモデルタイプを参照してください。
Model Properties
Edit ボタンで選択されたモデルタイプについての <output> Parameters ウィンドウが開きます。
モデルプロパティについての詳細は、NARXモデルタイプを参照してください。
Min/Max Time Lag
すべての入力と出力について、NARX構造において考慮すべき最大/最小タイムラグを入力します。このフィードバック値は「フィーチャー」とも呼ばれます。
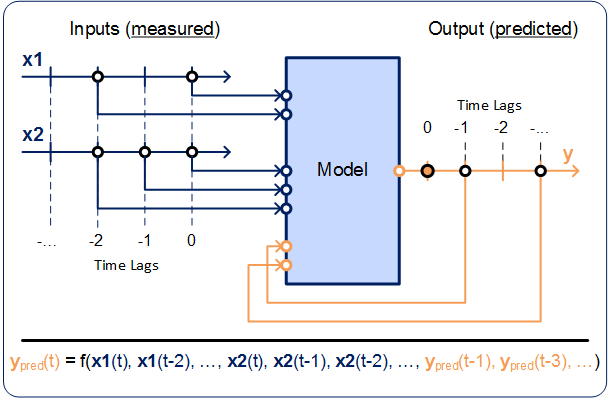
最初は、IACF分析の結果(位相プロットとACF/IACF出力(Phase Plot and ACF/IACF Outputs)を参照)を使用することをお勧めします。
- Initial States
Initial State of NARX Values ウィンドウが開き、NARX値の初期状態について設定を行うことができます。NARX値についての詳細は、NARXの初期値を参照してください。
Inputs/Output
Inputs テーブルには各入力の行が表示されます。Output テーブルには現在作業している出力の行(1行)が表示されます。
各テーブルには指定された数のタイムラグの列が表示されます。テーブルセル内のチェックボックスがオンの場合、そのフィーチャーが選択されていることを意味します。
Training Labels
モデルトレーニングを行いたいラベルを割り当てます。複数のラベルを使用する場合は、1つ以上のラベルに関連するすべてのデータが使用されます。
ラベルを割り当てるには、フィールドをダブルクリックして名前をキー入力します。リストに提示されたデータセットから選択することができます。
ラベルを削除するには、ラベルの x、または Del を使用します。
Validation Labels
検証データとして使用したいデータのラベルを割り当てます。複数のラベルを使用する場合は、1つ以上のラベルに関連するすべてのデータが使用されます。
ラベルを割り当てるには、フィールドをダブルクリックして名前をキー入力します。リストに提示されたデータセットから選択することができます。
ラベルを削除するには、ラベルの x、または Del を使用します。
注記 |
|---|
いずれのデータにも検証ラベルが割り当てられていない場合は、検証なしでトレーニングが行われます。ログウィンドウにメッセージが表示されます。Manage Datasets ウィンドウで、ラベルをデータに割り当てることができます。 |
Network Layout
Number of Layers
層の数を入力します。
Cell Memory Size
ニューラルネットワークのノード当たりのセルメモリサイズを入力します。一般的な値の範囲は[5, 20]です。実際のメモリセルのサイズはセルタイプに依存します。
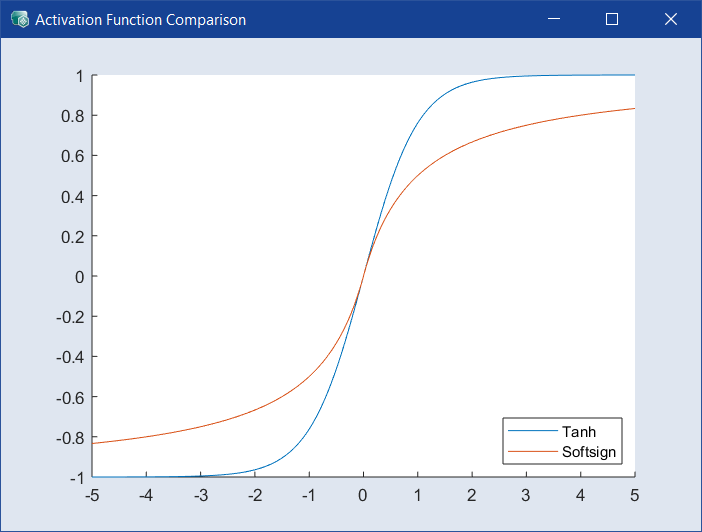
すべての層で使用される活性化関数を選択します。デフォルトは Tanh で、別の関数を使うと、精度は落ちても計算効率が良くなる可能性があります。ドロップダウンの隣の ![]() をクリックすると、
をクリックすると、![]() Activation Function Comparison ウィンドウ が開きます。
Activation Function Comparison ウィンドウ が開きます。
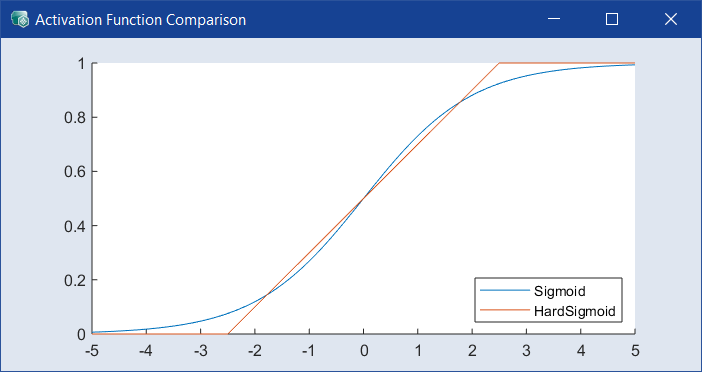
すべての層で使用されるリカレント活性化関数を選択します。デフォルトは Sigmoid で、別の関数を使うと、精度は落ちても計算効率が良くなる可能性があります。ドロップダウンの隣の ![]() をクリックすると、
をクリックすると、![]() Activation Function Comparison ウィンドウ が開きます。
Activation Function Comparison ウィンドウ が開きます。
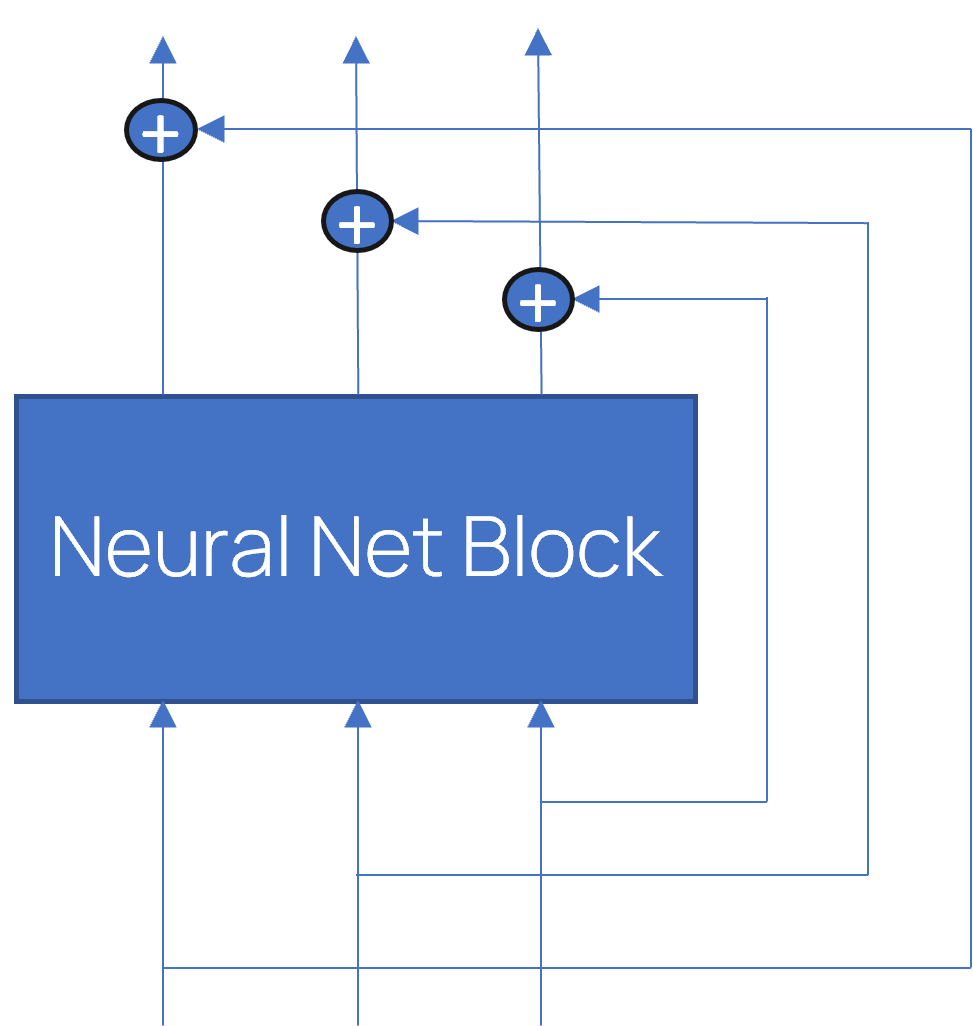
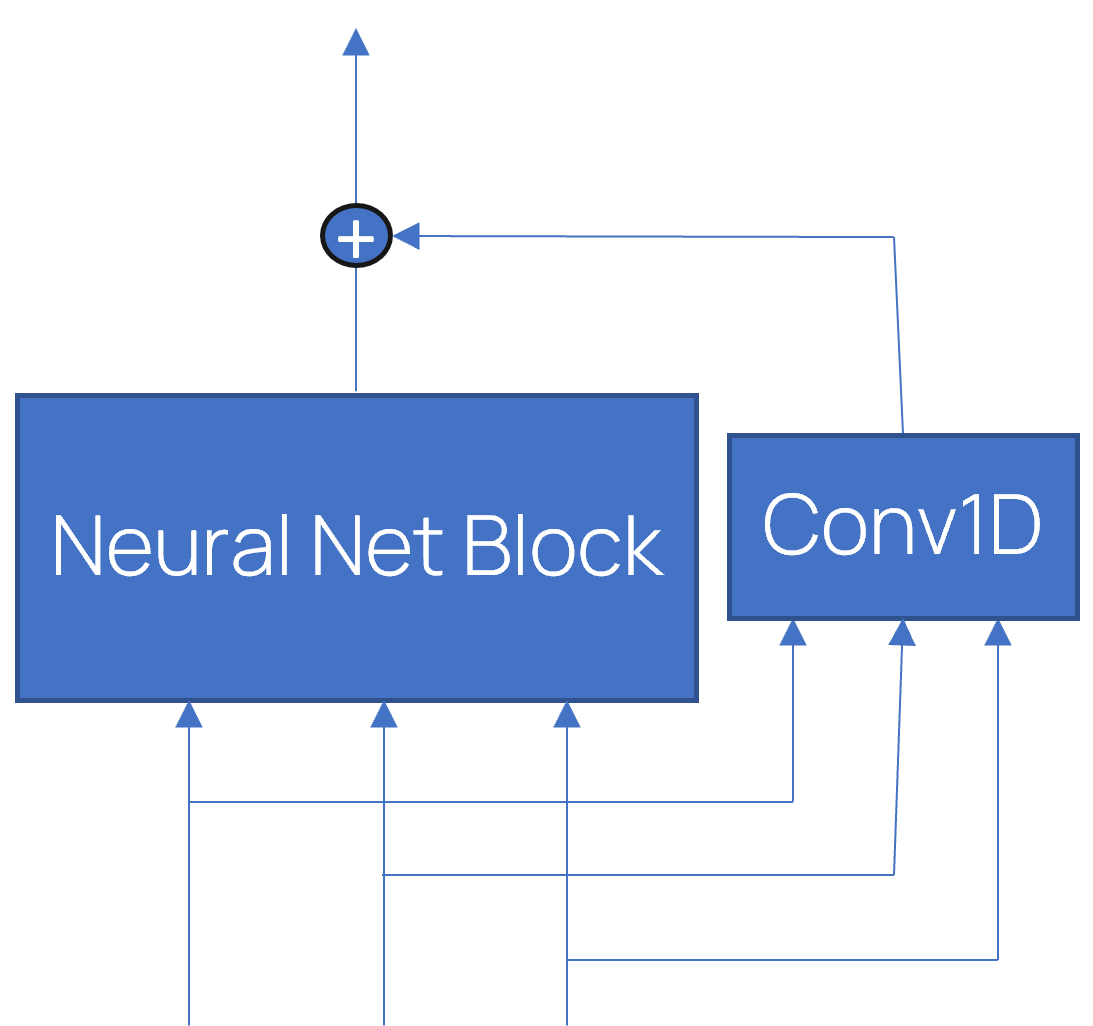
Use Skip Connections
層の入力をその出力に加えるには、これをオンにします。
入力と出力のサイズが一致しない場合、入力は追加の畳み込み層で処理されてから出力に追加されます。スキップ接続は、選択された層をスキップして情報を流すことを可能にするもので、トレーニングを簡素化し、ネットワークのパフォーマンスを向上させることが示されています。
Number of Network Parameters
現在の設定
Output Properties
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- log(y) - 対数
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を 表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。
表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Training Properties
Continue Training
新しいトレーニングを開始する代わりに、可能であれば既存のモデルトレーニングと反復を続行するには、このオプションをオンにします。Training Properties を変更して続行することができます。
Number of Multistarts
異なる開始値で行う反復の回数を入力します。値が大きいとモデル品質が向上しますが、モデルトレーニングの所要時間が長くなります。デフォルトは3です。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Training Loss
トレーニング不足のタイプを選択します。トレーニング不足は、モデルトレーニングの実行中に最小化される目標です。
Absolute はRMSE演算と等しくなります:
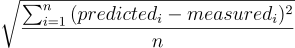
Relative は測定値と関連付けます:
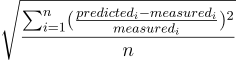
Transformed は Absolute に似ていますが、変換された空間においてトレーニング不足の計算を行うので、出力変換に依存します。
データを分割した配列のサイズを入力します。基盤となるオプティマイザは、ここで指定された長さに固定されたバッチを取得します。デフォルトは100です。
現在のデータの長さがこの程度のステップ数以下であれば、Lookback Length=100での最適化も可能ですが、スニペット長をより短くすることをお勧めします。値が小さいほどトレーニングが速くなります。
トレーニング中にランダムに非活性化するニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
トレーニング中に非活性化するリカレント状態のニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
トレーニング中に非活性化するリカレント状態のニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
Learn Initial States
このチェックボックスがオンの場合、最初の時間ステップの入力値と出力値に基づいてRNNモデルの初期状態が学習されるため、初期予測は与えられた出力と一致します。
モデルのエクスポート時に、希望する初期出力を定義することができます。
Plot RMSE during Training
トレーニングデータと検証データのRMSE値を![]() モデルトレーニング中に表示したい場合は、オンにします。
モデルトレーニング中に表示したい場合は、オンにします。
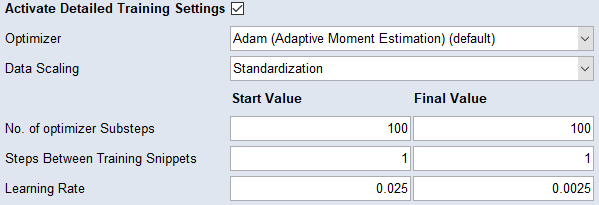
Activate Detailed Training Settings
チェックボックスをオンにすると、![]() Detailed Training Settings セクションが表示されます。
Detailed Training Settings セクションが表示されます。
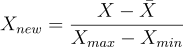 を [-1, 1] に含まれる長さ 1 の区間にスケーリングします。
を [-1, 1] に含まれる長さ 1 の区間にスケーリングします。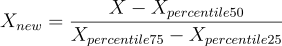
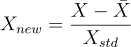
Network Layout
Number of Layers
層の数を入力します。
Number of Filters
各層のフィルタの数を指定します。
Kernel Size
各層のカーネルサイズを指定します。
注記 |
|---|
カーネルサイズと膨張率の設定は、モデルの受容野の長さ、つまり、現在の時間ステップの予測を計算するために、モデルが過去をどこまで見ることができるかを決定します。畳み込みニューラルネットワーク(Convolutional Neural Network)によるモデル予測を参照してください。 |
Dilation Rate
各層の膨張率を指定します。各時間的畳み込み層は、膨張率 r で膨張された Conv1d層を使用します。つまり、入力のrthごとの要素すべてが畳み込みに使用されます。たとえば、入力配列全体を使用したい場合は、i 番目の層に r=bi-1 を使用することができます(bは自然数 ≥ 2)。各層のデフォルトは r=1 です。
注記 |
|---|
カーネルサイズと膨張率の設定は、モデルの受容野の長さ、つまり、現在の時間ステップの予測を計算するために、モデルが過去をどこまで見ることができるかを決定します。畳み込みニューラルネットワーク(Convolutional Neural Network)によるモデル予測を参照してください。 |
Leaky ReLU Slope
CNN層の活性化関数Leaky ReLUを指定します。負の入力に対する傾きは、0(ReLU活性化)から1(線形活性化)までの区間で設定することができます。
 :活性化関数のプロットを、現在の傾き値で開きます。各フィールドに異なる値が入力されている場合は、値ごとに1つの関数がプロットされます。
:活性化関数のプロットを、現在の傾き値で開きます。各フィールドに異なる値が入力されている場合は、値ごとに1つの関数がプロットされます。
トレーニング中にランダムに非活性化するニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
Use Skip Connections
層の入力をその出力に加えるには、これをオンにします。
入力と出力のサイズが一致しない場合、入力は追加の畳み込み層で処理されてから出力に追加されます。スキップ接続は、選択された層をスキップして情報を流すことを可能にするもので、トレーニングを簡素化し、ネットワークのパフォーマンスを向上させることが示されています。
Receptive Field
モデルが考慮した過去の時間ステップの数が表示されます。カーネルサイズと膨張率の値に応じた値が動的に表示されます。この値(k)は、区間[t-(k-1),t]からの入力(すべてではない場合もあります)が、時間ステップtでの出力計算に使われることを意味します。
指定されたカーネルサイズと膨張率で生成された受容野の![]() スケマティック表現を開きます。
スケマティック表現を開きます。
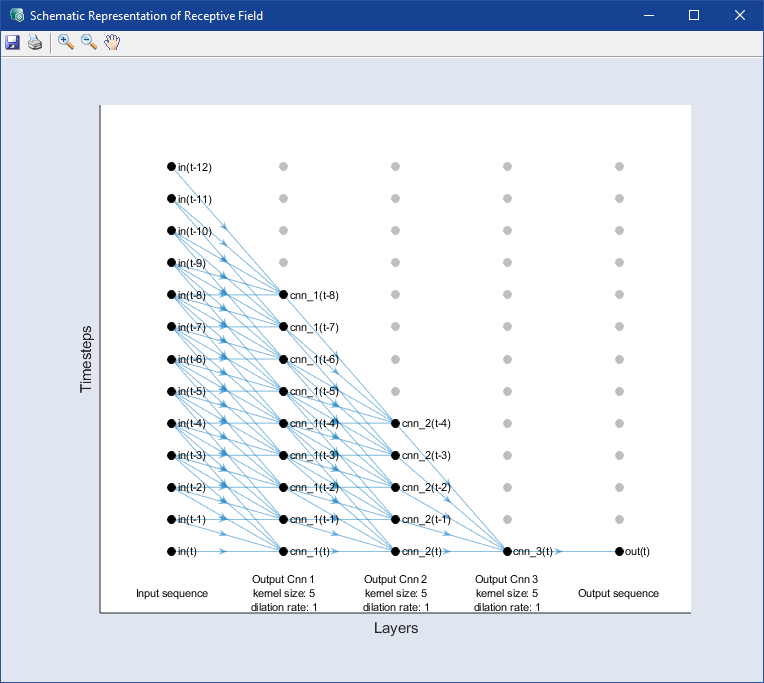
Number of Network Parameters
現在の設定
Output Properties
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- log(y) - 対数
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Training Properties
Continue Training
新しいトレーニングを開始する代わりに、可能であれば既存のモデルトレーニングと反復を続行するには、このオプションをオンにします。Training Properties を変更して続行することができます。
Number of Multistarts
異なる開始値で行う反復の回数を入力します。値が大きいとモデル品質が向上しますが、モデルトレーニングの所要時間が長くなります。デフォルトは3です。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Training Loss
トレーニング不足のタイプを選択します。トレーニング不足は、モデルトレーニングの実行中に最小化される目標です。
Absolute はRMSE演算と等しくなります:
Relative は測定値と関連付けます:
Transformed は Absolute に似ていますが、変換された空間においてトレーニング不足の計算を行うので、出力変換に依存します。
Snippet Length
データを分割した配列のサイズを入力します。これによりオプティマイザは、固定長(入力された値と受容野の長さの合計)の配列のバッチを取得します。スニペット長のデフォルト値は50です。
現在のデータの長さがこの程度のステップ数以下であれば、"Snippet Length" = 50での最適化も可能ですが、スニペット長を短くすることをお勧めします。値が小さいほどトレーニングが速くなります。
Plot RMSE during Training
トレーニングデータと検証データのRMSE値を![]() モデルトレーニング中に表示したい場合は、オンにします。
モデルトレーニング中に表示したい場合は、オンにします。
Activate Detailed Training Settings
チェックボックスをオンにすると、![]() Detailed Training Settings セクションが表示されます。
Detailed Training Settings セクションが表示されます。
Static Model Type
静的モデルのタイプを選択します。
モデルタイプの詳細については Staticモデルタイプを参照してください。
Model Properties Edit
クリックしてモデルのパラメータを編集します。
モデルプロパティについての詳細は、NARXモデルタイプを参照してください。
Start Training
クリックすると、現在の設定に基づいてモデルトレーニングが開始されます。
右側のアイコンは、モデルトレーニングの状態を示します。
 :モデルはまだトレーニングされていません。
:モデルはまだトレーニングされていません。
![]() :モデルはトレーニングされ、最新の状態になっています。
:モデルはトレーニングされ、最新の状態になっています。
![]() :モデルはトレーニングされましたが、データが古くなっています。コンフィギュレーション、トレーニングデータ、検証データが変更されています。
:モデルはトレーニングされましたが、データが古くなっています。コンフィギュレーション、トレーニングデータ、検証データが変更されています。
Meta Data
トレーニングデータセットと検証データセットの両方についてRMSE(二乗平均平方根誤差)とR²(決定係数)が表示され、モデルの精度と適合度を素早く確認することができます。
Measured vs. Predicted
測定値と予測値を可視化するウィンドウを開きます。ショートカットメニューで、表示するデータセット(All、Training、Validation、Test)を選択します。
Scope View
"Scope View" ウィンドウを開きます。ショートカットメニューで、表示するデータセット(All、Training、Validation、Test)を選択します。
Open in ASCMO-DYNAMIC
モデルコンフィギュレーションがASCMO-DYNAMICの新しいインスタンスで開き、そこでモデルの保存やエクスポートを行うことができます。
参照