NARXモデルタイプ
NARX Structure モデリングメソッドに基づくモデルには、以下のタイプがあります:
モデリングメソッド Recurrent Neural Network については、再帰型ニューラルネットワーク(Recurrent Neural Networks)によるモデル予測を参照してください。
|
注記 |
|---|
|
すべてのモデルタイプの概要とそれらの最適な使用法は、概要:モデルタイプの説明を参照してください。 |
ASC GP-Spectrumモデル
ここではASCMO Gaussian Process Spectrum(ASC GP-Spectrum)が標準のタイプです。
ASC GP-Spectrumモデリングアルゴリズムは、標準的なASCアルゴリズムを改良して、大量のデータセットを処理できるようにしたものです。
ASC GP-Spectrum を使用するには、基底関数の数(n_basis)を設定する必要があります。モデルトレーニングでは、データセット全体に含まれる情報が n_basis 個の仮想基本ポイントからなるセットに変換されます。n_basis の値が大きいほどモデリング結果が向上しますが、モデリングに掛かる時間は長くなります。推奨される値の範囲は 50 < n_basis < 200 です。
ASC GP-Spectrum 用のその他のモデルパラメータは、以下のように設定します。
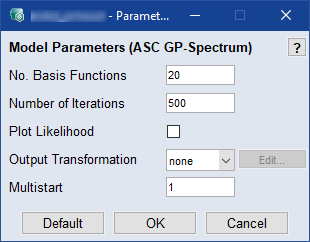
No. Basis Functions
早く収束させるには、実際のモデルトレーニングで使用するより小さなサイズ(20など)を指定してください。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Plot Likelihood
このオプションがオフの場合は、入力がクラス1に割り当てられる確率がプロットされます。
オンの場合は、しきい値以上の確率値がクラス1に割り当てられます。クラスのメンバ数がプロットされます。
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- log(y) - 対数
-
Bounded:上下限値内に制限されます。
 Edit をクリックして自動的に選択された上下限値を
Edit をクリックして自動的に選択された上下限値を 表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。
表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。 -
log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Multistart
モデルトレーニング実行中に異なる開始値でオプティマイザを実行する回数を入力します。値が大きいほど最適なモデルが見つかる確率が上がりますが、所要時間が長くなります。
注記 |
|---|
ASC GP-Spectrumタイプのモデルは各種エクスポートフォーマットのファイルにエクスポートできます。 |
ASC GP-SCS Model ー ASC GP-SCSモデル
ASCMO Gaussian Process Sparse Constant Sigma(ASC GP-SCS)タイプのモデルは、トレーニングデータの数が多い場合に推奨されます。以下のパラメータ設定が行えます。
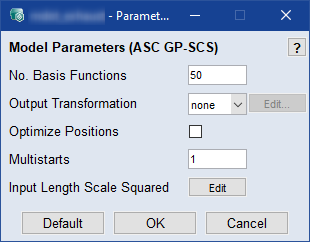
No. Basis Functions
早く収束させるには、実際のモデルトレーニングで使用するより小さなサイズ(20など)を指定してください。
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- log(y) - 対数
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Optimize Positions
このチェックボックスがオンの場合は、ランダムに選択されたトレーニングデータの位置において基底関数が使用される代わりに、最適化位置において仮想的(疑似的)入力が使用されます。
トレーニングに使用する入力の数は、"No. Basis Functions" オプションで指定します。
Multistart
モデルトレーニング実行中に異なる開始値でオプティマイザを実行する回数を入力します。値が大きいほど最適なモデルが見つかる確率が上がりますが、所要時間が長くなります。
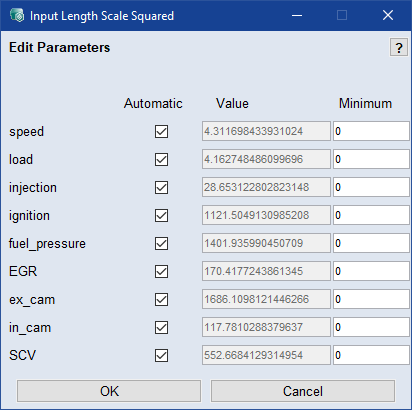
Input Length Scale Squared
Editをクリックすると、![]() Input Length Scale Squared ウィンドウが開きます。ここで各入力のハイパーパラメータを編集することができます。Automatic をオンにすると、その入力に対して適切なハイパーパラメータが自動設定されます。オフにすると、任意の値を入力することができます。入力のサイズに関するハイパーパラメータの値は、ガウス分布のベルカーブのコア幅です。長さのスケールは以下の式のrであるため、値が小さい方が関連性が高くなります:
Input Length Scale Squared ウィンドウが開きます。ここで各入力のハイパーパラメータを編集することができます。Automatic をオンにすると、その入力に対して適切なハイパーパラメータが自動設定されます。オフにすると、任意の値を入力することができます。入力のサイズに関するハイパーパラメータの値は、ガウス分布のベルカーブのコア幅です。長さのスケールは以下の式のrであるため、値が小さい方が関連性が高くなります:
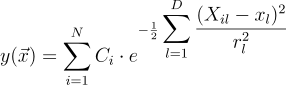
Default
すべてのパラメータをデフォルト値に戻します。
注記 |
|---|
ASC GP-SCSタイプのモデルは、INCA/MDAにはエクスポートできません。 |
ASC GP Model ー ASC GPモデル
ASCMO Gaussian Process(ASC GP)モデルタイプは、15個の入力に対してトレーニングデータが4000個までのデータセットに使用することができます。これはデフォルトのモデルタイプです。トレーニング時間とメモリ消費量は、特にデータポイントの数に応じて変化します。データポイントの量がさらに多い場合は、他のモデルタイプの方が適している場合があります。
以下のモデルパラメータを設定できます:
Automatic
モデルのトレーニング時に、自動的に最適なBox-Cox変換が決定されるようにしたい場合は、このチェックボックスをオンにします。
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。
以下から選択できます:
- none - 変換なし
- 1/y - 反転
- 1/sqrt(y) 平方根の逆数
- log(y) - 対数
- sqrt(y) - 平方根
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Advanced Settings がオン(File > Options > Advanced Settings)になっていると、出力のモデルトレーニングについてさらに詳細なパラメータを設定することができます。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Number of Multistarts
異なる開始値で行う反復の回数を入力します。値が大きいとモデル品質が向上しますが、モデルトレーニングの所要時間が長くなります。デフォルトは3です。
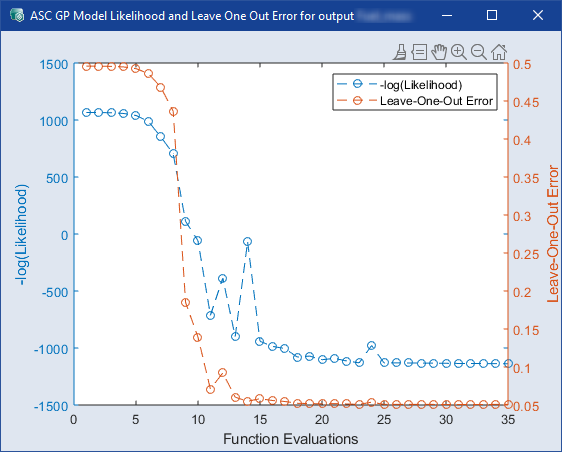
Plot Likelihood
このオプションをオンにすると、モデリング時に、対数尤度関数とLeave-One-Out誤差の値がランの関数として![]() 表示されます。
表示されます。
Max No. of Basis Functions
モデルトレーニングの基底関数の最大数を入力します。値が大きいとモデル品質が向上しますが、モデルトレーニングの所要時間が長くなります。デフォルトは4000です。トレーニングデータポイントとサブセットサイズのどちらか小さい方の値が、モデルの基底関数の数として使用されます。さらに多くのトレーニングデータポイントが使用可能な場合は、すべてのデータがトレーニングに使用されますが、結果のモデルは4000個の基底関数に制限されます。この場合は少し異なるトレーニングアルゴリズムが使用されますが、モデルの予測は同じ方法で行われます。
Sparse Subset Selection Method
"Max No. of Basis Functions" を超えるデータポイントがある場合に、トレーニングデータポイントを予備のサブセットに削減するために使用する方法を選択します。
Random(デフォルト):特定の選択基準を持たないサブセットのランダム選択。
GP-SCS like を選択すると、ガウスプロセス回帰を使用して、予測性能への影響に基き、関連するフィーチャーをサブセットに反復的に追加します。
Kernel
モデルトレーニングに使用されるカーネル関数を選択します。
Squared Exponential (ARD)(デフォルト):よりソフトなカーブ特性値を使用します。
Matern (ARD) は、よりハードなカーブ特性値でモデルのトレーニングを行います。強い非線形効果をよりシャープに、少ないノイズで解像することができます。これは過剰適合(オーバーフィッティング)を招く可能性があります。
Automatic Noise
ノイズレベルパラメータの最適化を自動的に行いたい場合は、これをオンにします。
Noise Level
許容される最大ノイズレベルの値を入力します。このフィールドは、"Automatic Noise" チェックボックスがオフになっている場合のみ使用できます。
Lower Bound Noise
ノイズレベルパラメータの最小値を入力します。このフィールドは、"Automatic Noise" チェックボックスがオンになっている場合のみ使用できます。
Linear Extrapolation
データの基礎的傾向を学習し、測定領域外にその傾向を示すリニアモデルを使用したい場合は、オンにします。
Modeling Criterion
モデルトレーニングに使用されるモデリング目標を選択します。
Default:likelihoodに基づきます。
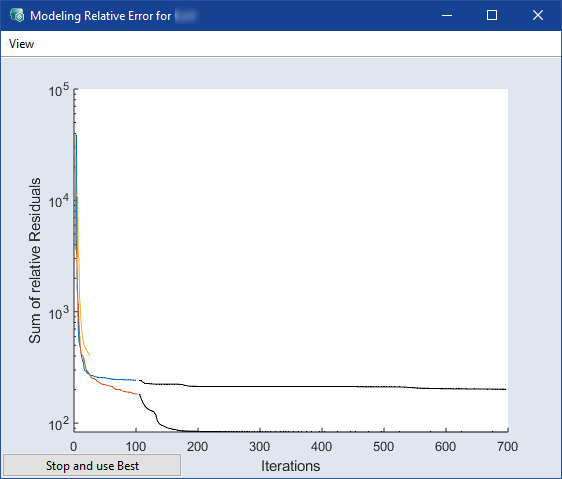
Relative Error:誤差を実際の値で割った商((測定データ - 予測データ) / 測定データ * 100)です。最適化の実行中は
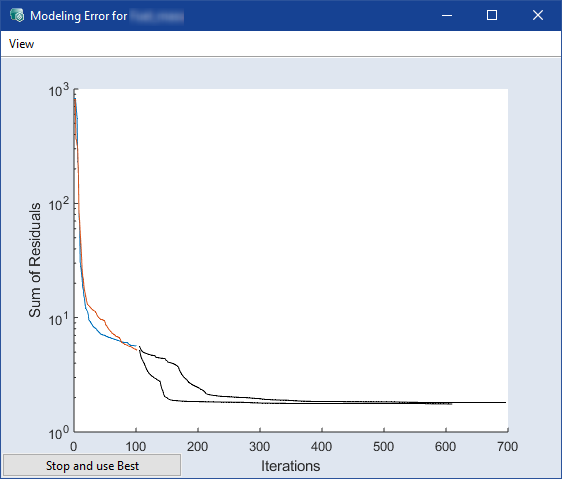
可視化ウィンドウがポップアップ表示され、ここで手動で最適化を停止してその時点までの最良の結果を使用することができます。
Input Length Scale Squared
Editをクリックすると、![]() Input Length Scale Squared ウィンドウが開きます。ここで各入力のハイパーパラメータを編集することができます。Automatic をオンにすると、その入力に対して適切なハイパーパラメータが自動設定されます。オフにすると、任意の値を入力することができます。入力のサイズに関するハイパーパラメータの値は、ガウス分布のベルカーブのコア幅です。長さのスケールは以下の式のrであるため、値が小さい方が関連性が高くなります:
Input Length Scale Squared ウィンドウが開きます。ここで各入力のハイパーパラメータを編集することができます。Automatic をオンにすると、その入力に対して適切なハイパーパラメータが自動設定されます。オフにすると、任意の値を入力することができます。入力のサイズに関するハイパーパラメータの値は、ガウス分布のベルカーブのコア幅です。長さのスケールは以下の式のrであるため、値が小さい方が関連性が高くなります:
Rounding Threshold
異常予測しきい値(その値を下回るとモデルの予測値が自動的に0に設定され、それ以外は1になります)を入力します。しきい値は、Receiver Operating Characteristic(Model > Anomaly Detection: Receiver Operating Characteristic)に表示されます。
ASC Compressed Model ー ASC圧縮モデル
このモデルタイプでは、モデル内の基底関数の数を制限することができます
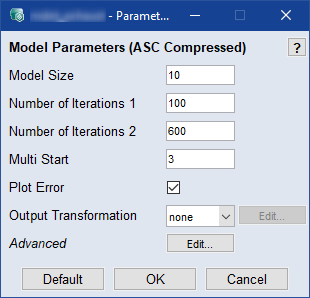
Model Size
圧縮モデル用の基底関数の数を入力します。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Multistart
モデルトレーニング実行中に異なる開始値でオプティマイザを実行する回数を入力します。値が大きいほど最適なモデルが見つかる確率が上がりますが、所要時間が長くなります。
Plot Error
チェックボックスをオンにすると、モデルトレーニング中に発生した誤差の情報が表示されます。
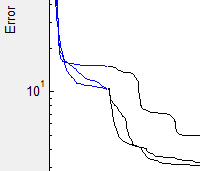
RMSEをビットマップグラフィックとして保存するには、メインウィンドウ内の View > Save as Bitmap を使用します。
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- 1/y - 反転
- 1/sqrt(y) 平方根の逆数
- log(y) - 対数
- sqrt(y) - 平方根
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
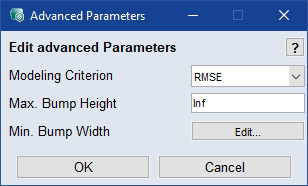
Advanced
Edit をクリックして、![]() 詳細パラメータ を編集します。
詳細パラメータ を編集します。
MLP Model ー MLPモデル
Bosch ECU用フラットバッファフォーマットにエクスポートすることができるMLP(Multilayer Perceptron:多層パーセプトロン)モデルです。
以下のパラメータ設定が行えます。
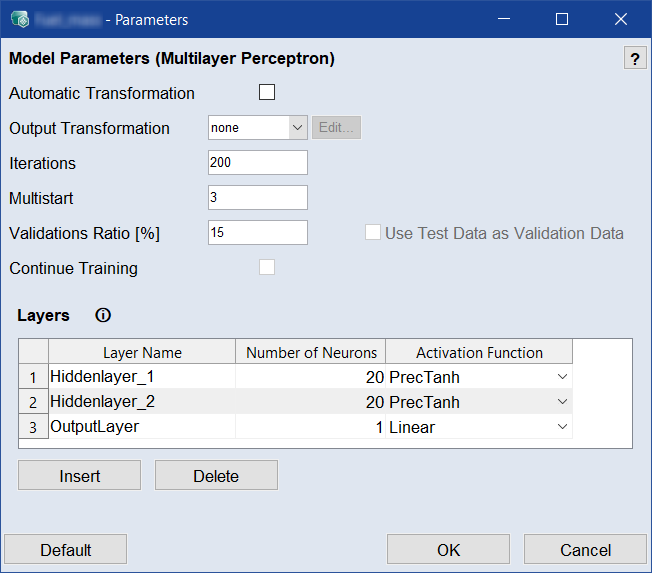
Automatic
モデルのトレーニング時に、自動的に最適なBox-Cox変換が決定されるようにしたい場合は、このチェックボックスをオンにします。
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。
以下から選択できます:
- none - 変換なし
- 1/y - 反転
- 1/sqrt(y) 平方根の逆数
- log(y) - 対数
- sqrt(y) - 平方根
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
Iterations
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
Multistart
モデルトレーニング実行中に異なる開始値でオプティマイザを実行する回数を入力します。値が大きいほど最適なモデルが見つかる確率が上がりますが、所要時間が長くなります。
Validations Ratio [%]
トレーニングデータからランダムに選択される検証サンプルの相対数(単位:%)を入力します。
Use Test Data as Validation Data
テストデータを検証データとして使用したい場合は、チェックボックスをオンにします。
Continue Training
新しいトレーニングを開始する代わりに、可能であれば既存のモデルトレーニングと反復を続行するには、このオプションをオンにします。Training Properties を変更して続行することができます。たとえば、複雑な活性化関数でトレーニングした後、ECUにとってより効率的な関数に切り替え、シームレスにトレーニングを続けることができます。
Layers
多層パーセプトロンの層を設定します。
リストから活性化関数を選択します。
Linear: y = x
ReLU: y = max(0, x)
LeakyReLU: y = max(0.01 * x, x)
Sigmoid: y = 1 / (1 + exp(-x))
PrecTanh: y = 2 / (1 + exp(-2 * x)) - 1
Elliotsig: y = x / (1 + abs(x))
Insert:クリックして
Delete:選択されている1つまたは複数の層を削除します。
Linearモデル
モデルタイプ Linear については、以下のパラメータ設定が行えます。
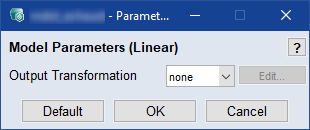
Output Transformation
出力の変換タイプを選択します。変換を利用することによりモデル予測を改善できます。トレーニングデータの値に負またはゼロが含まれる場合、一部の変換は使用不可となります。
以下から選択できます:
- none - 変換なし
- log(y) - 対数
Bounded:上下限値内に制限されます。
Edit をクリックして自動的に選択された上下限値を表示、または手動で下限値と上限値を定義することができます。これらを手動で定義するには、Automatic チェックボックスをオフにします。上下限値はトレーニングデータの範囲内である必要があります。log(y+c):対数 + 定数
Edit をクリックして自動的に選択された対数シフトを表示、または手動でシフト値を定義することができます。これを手動で定義するには、Automatic チェックボックスをオフにします。
注記 |
|---|
Linear タイプのモデルは、エクスポートできません。 |
参照