Model Configurations:Anomaly Detection (Autoencoder)
モデリングメソッド Anomaly Detection (Autoencoder)(Model > Configurations)が選択されていると、<output> タブの Model Configuration 領域には以下のエレメントが含まれます。出力ごとに個別のタブがあります。
.png)
Output Properties 領域とウィンドウ最下部のボタン行についての説明は、 Model Configurations (ASCMO-DYNAMIC)を参照してください。
Training Labels
モデルトレーニングを行いたいラベルを割り当てます。複数のラベルを使用する場合は、1つ以上のラベルに関連するすべてのデータが使用されます。
ラベルを割り当てるには、フィールドをダブルクリックして名前をキー入力します。リストに提示されたデータセットから選択することができます。
ラベルを削除するには、ラベルの x、または Del を使用します。
Validation Labels
検証データとして使用したいデータのラベルを割り当てます。複数のラベルを使用する場合は、1つ以上のラベルに関連するすべてのデータが使用されます。
ラベルを割り当てるには、フィールドをダブルクリックして名前をキー入力します。リストに提示されたデータセットから選択することができます。
ラベルを削除するには、ラベルの x、または Del を使用します。
|
注記 |
|---|
|
いずれのデータにも検証ラベルが割り当てられていない場合は、検証なしでトレーニングが行われます。ログウィンドウにメッセージが表示されます。Manage Datasets ウィンドウで、ラベルをデータに割り当てることができます。 |
Network Layout
Number of Layers
層の数を入力します。
Cell Memory Size
ニューラルネットワークのノード当たりのセルメモリサイズを入力します。一般的な値の範囲は[5, 20]です。実際のメモリセルのサイズはセルタイプに依存します。
最終層:セルメモリサイズは入力の数なので、変更できません。
第1層と第3層:セルメモリサイズは入力の数の2倍です。
第2層:セルメモリサイズは入力の数から1を引いた数で、「ボトルネック」と呼ばれます。
より多くの、または少ない層を使用することができますが、ボトルネックは常に必要であり、最終層の数は必ず入力ニューロンの数となります。
注記:1つのセルのメモリサイズは、必ず入力の総数より小さくする必要ありますい。
すべての層で使用される活性化関数を選択します。デフォルトは Tanh で、別の関数を使うと、精度は落ちても計算効率が良くなる可能性があります。ドロップダウンの隣の ![]() をクリックすると、
をクリックすると、![]() Activation Function Comparison ウィンドウ が開きます。
Activation Function Comparison ウィンドウ が開きます。
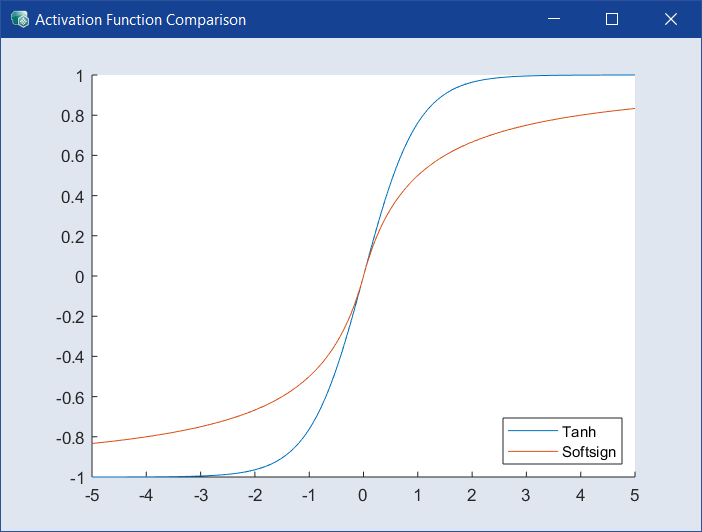
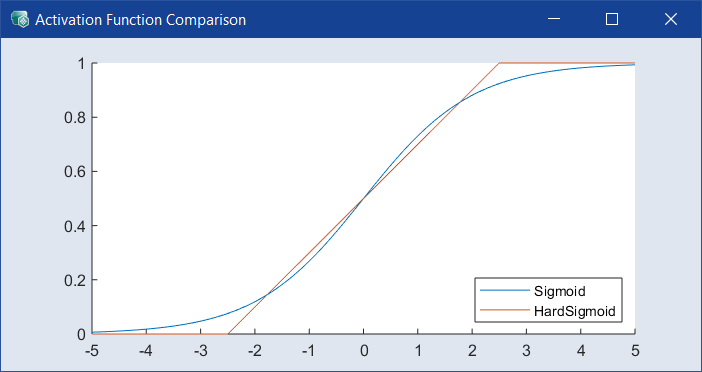
すべての層で使用されるリカレント活性化関数を選択します。デフォルトは Sigmoid で、別の関数を使うと、精度は落ちても計算効率が良くなる可能性があります。ドロップダウンの隣の ![]() をクリックすると、
をクリックすると、![]() Activation Function Comparison ウィンドウ が開きます。
Activation Function Comparison ウィンドウ が開きます。
Number of Network Parameters
現在の設定
Training Properties
Continue Training
新しいトレーニングを開始する代わりに、可能であれば既存のモデルトレーニングと反復を続行するには、このオプションをオンにします。Training Properties を変更して続行することができます。
Number of Multistarts
異なる開始値で行う反復の回数を入力します。値が大きいとモデル品質が向上しますが、モデルトレーニングの所要時間が長くなります。デフォルトは3です。
モデルトレーニングにおいて実施する反復回数を入力します。検証データで10回反復してもモデル性能が向上しない場合、トレーニングは中止されます。ディープラーニングにおいて、これはよく「エポック数」と呼ばれます。
データを分割した配列のサイズを入力します。基盤となるオプティマイザは、ここで指定された長さに固定されたバッチを取得します。デフォルトは100です。
現在のデータの長さがこの程度のステップ数以下であれば、Lookback Length=100での最適化も可能ですが、スニペット長をより短くすることをお勧めします。値が小さいほどトレーニングが速くなります。
トレーニング中にランダムに非活性化するニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
トレーニング中に非活性化するリカレント状態のニューロンの割合を、0~0.9の範囲で入力します。非活性化は、ニューロンの重みを一時的に0にするものです。これにより、過剰適合(オーバーフィッティング)を回避することができます。入力された値が0の場合は非活性化されず、0.1にすると10%のニューロンが一時的に0に設定されます。一般的な値の範囲は[0, 0.2]です。
Plot RMSE during Training
トレーニングデータと検証データのRMSE値を![]() モデルトレーニング中に表示したい場合は、オンにします。
モデルトレーニング中に表示したい場合は、オンにします。
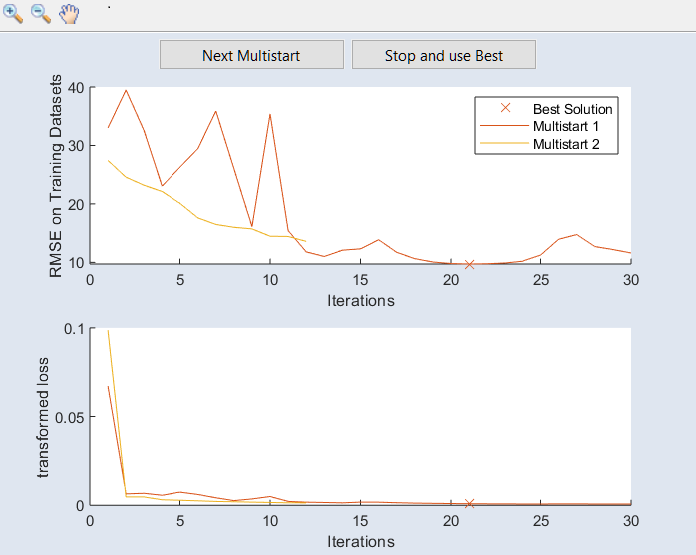
Activate Detailed Training Settings
チェックボックスをオンにすると、![]() Detailed Training Settings セクションが表示されます。
Detailed Training Settings セクションが表示されます。
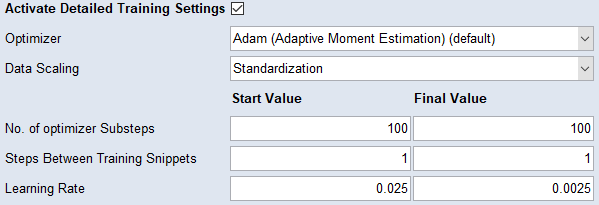
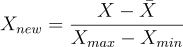 を [-1, 1] に含まれる長さ 1 の区間にスケーリングします。
を [-1, 1] に含まれる長さ 1 の区間にスケーリングします。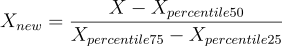
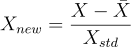
Anomaly Percentile
正常とされる再構成誤差の百分位数を入力します。モデル選択に検証データセットが使用されている場合は、この値は検証データに基づいて計算され、そうでない場合はトレーニングデータに基づいて計算されます。値は異常スコアの0.5にマッピングされます。
Use Signalwise Percentile Values
各信号について個別にエラーしきい値を計算し、合計スコアを個々のスコアの最大値に設定したい場合は、オンにします。
Smoothing
メディアンフィルタのステップ数として、データポイントのウィンドウサイズの値を入力します。異常予測のため、信号が平滑化されます。これによって、より良い結果が導き出されます。
Smoothing Window Centered
スムージングウィンドウの中心を評価点にしたい場合、つまり未来の点も考慮したい場合は、オンにします。オフにすると、スムージングウィンドウでの計算に過去のポイントのみが使用されます。
Round Score
オンの場合はスコアが丸められ、しきい値を下回ると0、そうでない場合は1に設定されます。
オフの場合、スコアは[0,1]の連続値になります。
Rounding Threshold
異常予測しきい値(その値を下回るとモデルの予測値が自動的に0に設定され、それ以外は1になります)を入力します。しきい値は、Receiver Operating Characteristic(Model > Anomaly Detection: Receiver Operating Characteristic)に表示されます。
Inputs used in Model Training
この領域にはモデルのすべての入力が表示されます。ここで各入力をモデルトレーニングに含めるかどうかを指定することができます。
デフォルトにおいては、すべての入力が含まれます。
参照
Model Configurations (ASCMO-DYNAMIC)
Model Configurations:Recurrent Neural Network (RNN)