最適化アルゴリズム
Optimization(最適化)ステップでは、以下の最適化アルゴリズムを選択することができます:
勾配降下最適化は、初期値として設定されたワーキングパラメータセットで開始し、コスト関数の勾配を使用して、コスト関数の最小値を目指して最急降下方向へ反復的に向かいます。勾配降下オプティマイザは局所最小値しか探索しないため、最適化の開始位置が重要になります。
ASCMO-MOCAは、関数の勾配を解析的に計算します。外部モデル(Simulink、FMUモデルなど)からの勾配は、有限差分法を用いて計算します。これにより、オプティマイザは最小回数の関数評価によって素早く局所最小値を求めることができます。メモリ消費量は少なくとも、データポイント数にパラメータ数を乗じて、最適化アルゴリズム自体に2倍を乗じたものとなります。
グローバルオプティマイザは勾配なしオプティマイザで、グローバル最適解(大域的最適解)の探索を試みるものです。最適化問題に対するいくつかのランダムな解の候補が探索空間全体に広がっている状態から開始します。その後探索空間は、より良い正確な解に絞り込まれていきます。最適化が完璧に最適解にヒットするとは限らないので、グローバル最適化から始めてグローバル最適解を見つけ、さらに続けて勾配降下最適化を行って結果を洗練させることができます。
ASCMO-MOCAにおける典型的な最適化問題は、マップとカーブの最適化です。このような最適化問題には通常多くのパラメータが含まれ(たとえば、20x20のマップには400のパラメータがあります)、グローバルオプティマイザは良い解を見つけるために多くの反復を必要とすることがあります。
勾配なしのグローバル最適化は、関数/モデルの勾配が連続的でなくても解を見つけることができます。これは、モデルが数値やパラメータの固定小数点表現で実装され、入力や出力が離散的である場合に起こります。また、モデルが64ビット浮動小数点数ではなく32ビット浮動小数点数で実装されている場合にも起こります。
Default (Gradient Descent)
これは勾配降下最小二乗法によるオプティマイザです。これがデフォルトのオプティマイザとして選ばれたのは、最適化タスクに多くのパラメータが含まれる場合に優れた性能を発揮するためで、マップとカーブを使用するような場合に適しています。
残差は最適化アルゴリズムにベクトルとして入力されるため、オプティマイザは100点のデータセットに対して100個の残差を取得します。これは計算コストが高くなりますが、良い最適化結果につながります。
残差はオプティマイザによって暗黙のうちに2乗されるので、参照値との差は常に最小化されます。最小化または最大化を行うには、最適化する低値と高値を明示的に指定する必要があります。
出力は0から1000の範囲です。最大化を行うには、最適化目標をminarg(y(x)-1000)と定義します。
ローカルな制限は、和の式の一部(W * Constraint)として最適化に含まれます。ASCMOにおいては、これをソフト制限と呼びます。このようなローカルな制限の重みは、制限が満足されるまで10回の反復ごとに増加します。
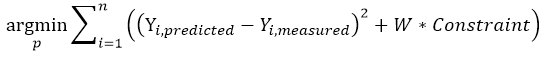
最適化実行中に制限違反が生じると、制限の重みが増加します。これでは不十分であり、最適化後も制限違反が存在する可能性があります。
用途:勾配降下最適化は、MOCAが扱う典型的な問題に対する理想的なアルゴリズムです。大量のメモリを必要としますが、高速で良好な結果をもたらします。他の最適化アルゴリズムは、以下に示すように特定の状況でのみ検討するようにしてください。
Respect Constraints (Gradient Descent)
これも勾配降下最小二乗法によるオプティマイザですが、制限が考慮されます。
オプティマイザは、制限をハード限界値として扱います。制限違反しない限りは、デフォルトのオプティマイザの方が好ましいでしょう。デフォルトオプティマイザで最適化した後に制限違反が認められた場合は、このアルゴリズムを使用します。
用途:この最適化アルゴリズムは、最適化実行後にローカル制限違反が発生した場合に役立ちます。まずデフォルトの最適化アルゴリズムを試行し、ローカル制限の重みを、たとえば、10、100、1000、...というように段階的に増加させていくことを推奨します。このアプローチに失敗した場合、本アルゴリズムが制限内で解を見つける可能性があります。
Gradient-free Optimizer
勾配を含まないオプティマイザは、最適化にシンプレックスアルゴリズムを使用します。このアルゴリズムは勾配に依存しないため、勾配降下アルゴリズムよりも多くの反復を必要とします。一般的に、勾配降下オプティマイザほど良い解は得られません。
この勾配なしオプティマイザは、関数/モデルの勾配が連続的でない場合に使用します。これは、モデルが数値やパラメータの固定小数点表現で実装され、信号が離散的である場合に起こります。また、モデルが64ビット浮動小数点数ではなく32ビット浮動小数点数で実装されている場合にも起こります。
用途:この最適化アルゴリズムは、内部で固定小数点表現を使用するなど、パラメータの小さな変化に敏感でない外部モデルに適しています。外部モデルが倍精度ではなく単精度(32ビット)を使用している場合は、有限差分係数を20,000に増やし、デフォルトのオプティマイザを使用することを検討してください。
Surrogate Optimizer (Global Optimization)
サロゲートオプティマイザは、グローバル最適解の探索を試みます。最初にサロゲートモデルを構築し、元の関数/モデルの代わりにそれを最適化します。これは、関数/モデルの評価に時間がかかるような場合に便利です。
用途:この最適化アルゴリズムは、時間がかかる外部モデルの評価に役立ちます。最適化のために、迅速に評価可能な代替モデルが構築されます。
Genetic Algorithm (Global Optimization)
遺伝的アルゴリズムは、グローバル最適解の探索を試みます。これは、自然淘汰とゲノム交換にヒントを得たものです。ランダムな解の候補(ここでは「集団」と呼びます)から開始します。詳細はWikipedia:Genetic Algorithmを参照してください。母集団のサイズがメモリ消費量に大きく影響します。多くの信号やデータを含む最適化タスクは、メモリ不足の問題を引き起こす可能性があります。母集団のサイズを小さくすることで、メモリを解放することができます。このアルゴリズムはすべての候補解をベクトル化するので、FMUモデルやTSimモデルのモデル評価を並行して実行することができます。
用途:この最適化アルゴリズムは、感度が低いモデルに適した勾配フリー最適化アルゴリズムです。主な目的は、特にデフォルトの最適化アルゴリズムがローカル最小値に陥る可能性がある場合に、グローバル最小値を見つけることです。このアルゴリズムはデフォルトの最適化アルゴリズムよりもメモリ使用量が少ない一方で、同様の結果を得るまでに時間がかかる場合があります。
Simulated Annealing (Global Optimization)
焼きなまし法は、グローバル最適解の探索を試みます。最適化はランダムな候補解から始めます。高い初期温度を使用するため、大きなパラメータ変更が可能です。何回かの反復により温度が下がるにつれてパラメータの変化が制限されるようになり、より正確な解を見つけることが可能になります。詳細はWikipedia:Simulated Annealingを参照してください。粒子の数がメモリ消費量に大きく影響します。多くの信号やデータを含む最適化タスクは、メモリ不足の問題を引き起こす可能性があります。粒子の数を減らすことで、メモリを解放することができます。
用途:この最適化アルゴリズムは、感度が低いモデルに適した勾配フリー最適化アルゴリズムです。主な目的は、特にデフォルトの最適化アルゴリズムがローカル最小値に陥る可能性がある場合に、グローバル最小値を見つけることです。このアルゴリズムはデフォルトの最適化アルゴリズムよりもメモリ使用量が少ない一方で、同様の結果を得るまでに時間がかかる場合があります。
Particle Swarm (Global Optimization)
量子群最適化は、グローバル最適解の探索を試みます。最適化はランダムな候補解(ここでは「粒子」と呼びます)から開始します。各粒子は位置と速度を持ちます。最適化は高速で始まり、何度か繰り返すうちに速度が低下して、より正確な解を見つけることができます。詳細はWikipedia:Particle Swarm Optimizationを参照してください。多くの信号やデータを含む最適化タスクは、メモリ不足の問題を引き起こす可能性があります。粒子の数を減らすことで、メモリを解放することができます。このアルゴリズムはすべての候補解をベクトル化するので、FMUモデルやTSimモデルのモデル評価を並行して実行することができます。
用途:この最適化アルゴリズムは、感度が低いモデルに適した勾配フリー最適化アルゴリズムです。主な目的は、特にデフォルトの最適化アルゴリズムがローカル最小値に陥る可能性がある場合に、グローバル最小値を見つけることです。このアルゴリズムはデフォルトの最適化アルゴリズムよりもメモリ使用量が少ない一方で、同様の結果を得るまでに時間がかかる場合があります。