異常検出によるモデリング
異常検出アルゴリズムは、データセット内で他のデータと大きく異なる、異常または疑わしいデータポイントを特定する目的で用いられます。このようなポイントは、「外れ値」、「異常点」、または単に「異常」と呼ばれます。
これには2つの主要なシナリオがあります。1つ目は、異常がどのようなものであるかがわかっている場合です。この場合、機械学習モデルを教師ありの方法で学習させることができます。つまり、トレーニングプロセスにおいて、正常なデータと異常なデータの両方のクラスにアクセスすることができ、二値分類器のようなものを学習させることが可能です。このようにトレーニングされたモデルは、既知の異常を識別するのに非常に優れていると期待されますが、新しい未知の異常に直面したときにモデルがどのような挙動を示すかは、不明です。
より一般的なユースケースとしては、基礎となるシステムの正常な動作を表す多くのデータにはアクセスできても、異常なデータへのアクセスは、(もしあったとしても)非常に限られており、異常なデータがどのように見えるかが不明である、ということがよくあります。しかし、センサの老朽化やサブシステムの故障によるデータのドリフト、といった異常な事象を検出することは必要不可欠です。このようなシナリオでは、機械学習モデルをトレーニングして、正常な動作がどのように見えるかを学習させることが主な目的となります。それにより、期待される動作からの逸脱を「異常」としてマークすることができるようになります。このようなモデルは、いわゆる「教師なし学習」でトレーニングされ、トレーニングプロセスにおいては正常な動作を表すデータにのみアクセスします。ASCMO-DYNAMICには、後者のユースケースをカバーする2つのモデルタイプ(主成分分析(PCA)モデルタイプとオートエンコーダ モデルタイプ)があります。
どちらのモデルタイプも、「次元の削減」という考えに基づいています。技術システムに由来する高次元のデータにはたいてい、相関関係、依存関係、冗長性などが含まれています。したがって、理論的には、重要な情報を失うことなくデータを低次元空間に埋め込むことが可能です。その逆に、低次元の埋め込み空間から元の空間へのマッピングが存在し、埋め込み表現から元のデータを再構築することが可能です。モデルは、通常の行動を表すデータに基づいて、埋め込みマッピングと再構成マッピングを学習するようにトレーニングされます。したがって、このモデルは正常なデータを非常にうまく再構成することが期待できますが、異常なデータを再構成すると誤差が大きくなります。このようなモデルは、元の入力データとその再構成の間の再構成誤差を分析することで、異常検出システムとして利用することができます。誤差が小さい場合は正常なデータが存在することを示し、誤差が大きい場合は異常な事象があることを示します。
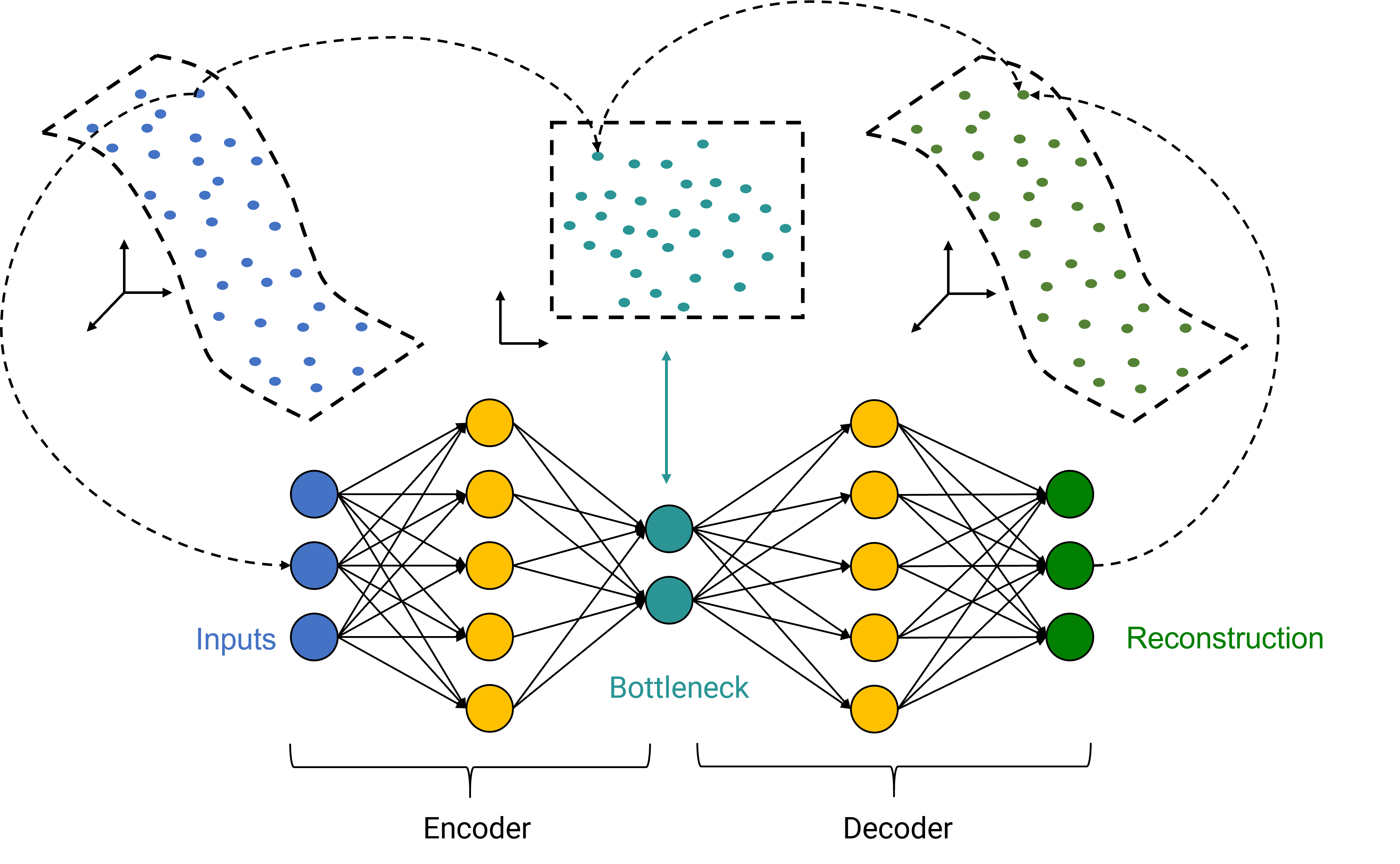
図26: 次元削減スキーム
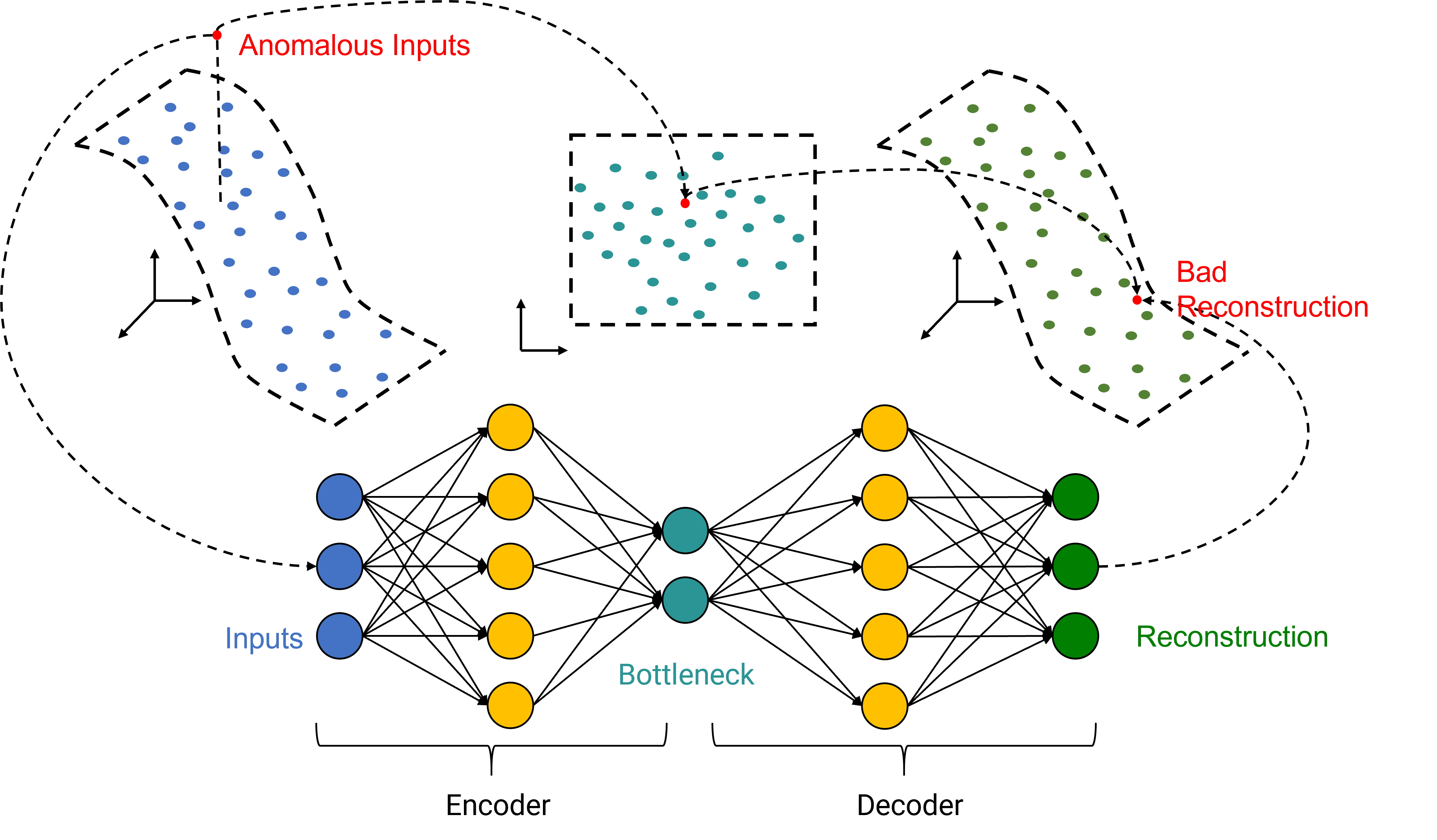
図27: 次元削減スキーム - 異常入力