Modeling with Anomaly Detection
Anomaly detection algorithms are used to identify data points in a data set that are unusual or suspicious because they differ significantly from the rest of the data. These points are referred to as outliers, anomalous points, or simply anomalies.
There are two main scenarios. In the first one, it is known what an anomaly looks like. In this case, a machine learning model can be trained in a supervised manner, i.e., during the training process one has access to both classes, the normal and anomalous data, and for example, a binary classifier can be trained. Such a trained model is expected to be very good at identifying known anomalies, but it is not clear how the model will behave when confronted with new and previously unknown anomalies.
The more common use case is that one has access to a lot of data representing the normal behavior of the respective underlying system, but there is very limited access to anomalous data (if at all), and often it is unknown how anomalous data looks like. Nevertheless, it is essential to detect anomalous events like the drift of data caused by an aged sensor or the failure of a subsystem. The main idea in these kind of scenarios is to train a machine learning model in such a way that it learns what normal behavior looks like. Any deviation from the expected behavior can then be marked as anomaly. Such models are trained in a so called unsupervised learning setting, meaning that during the training process one just has access to data representing the normal behavior. There are two model types in ASCMO-DYNAMIC that cover the latter use case: the Principal Component Analysis (PCA) Model Type and the Autoencoder Model Type .
Both model types are based on the same idea: dimensionality reduction. High dimensional data originating from an underlying technical system often contains correlations, dependencies or redundancies. Therefore, it is theoretically possible to embed the data in a lower dimensional space without losing significant information. Vice versa, there is a mapping from the lower dimensional embedding space to the original space that allows the original data to be reconstructed from its embedded representation. A model is trained to learn the embedding mapping and the reconstruction mapping based on data representing normal behavior. Thus, the model can be expected to reconstruct normal data quite well, while reconstructing anomalous data has a larger error. Such a model can be used as anomaly detection system by analyzing the reconstruction error between original input data and its reconstruction. While small errors are a sign of the presence of normal data, large errors indicate an anomalous event.
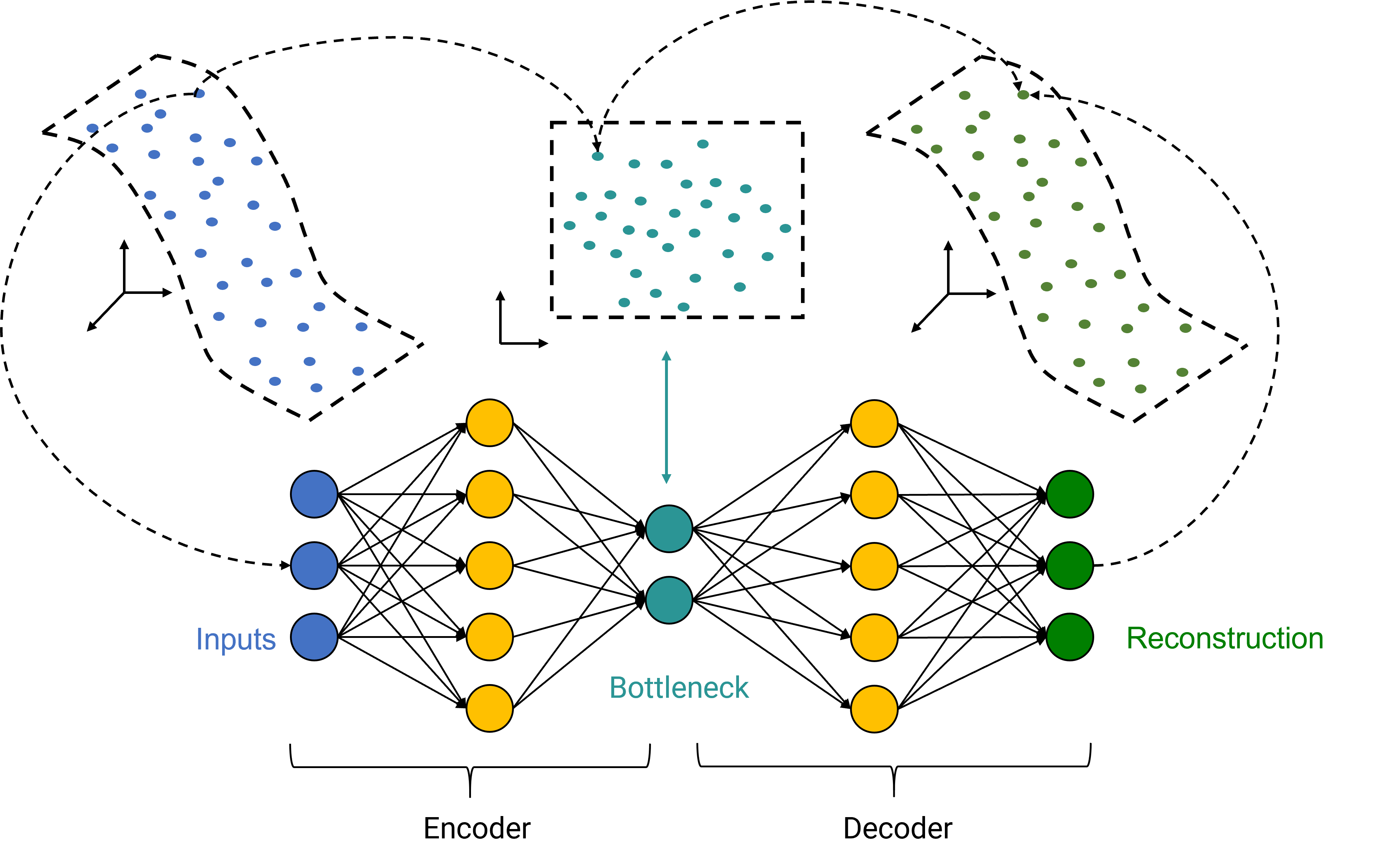
Fig. 26: Dimensionality Reduction Scheme
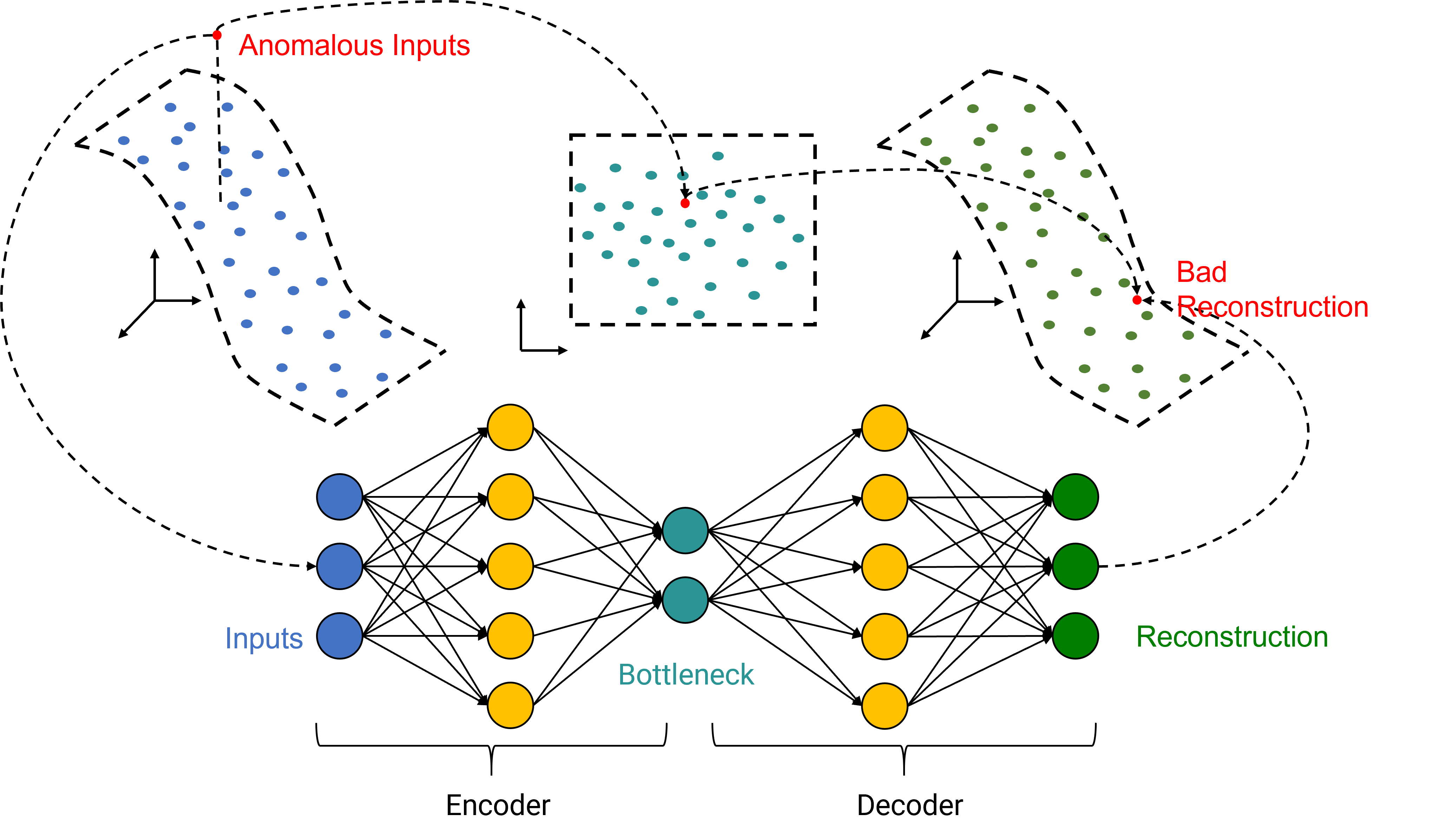
Fig. 27: Dimensionality Reduction Scheme - Anomalous Inputs