アルゴリズムの詳細(関数同定問題 - Symbolic Regression)
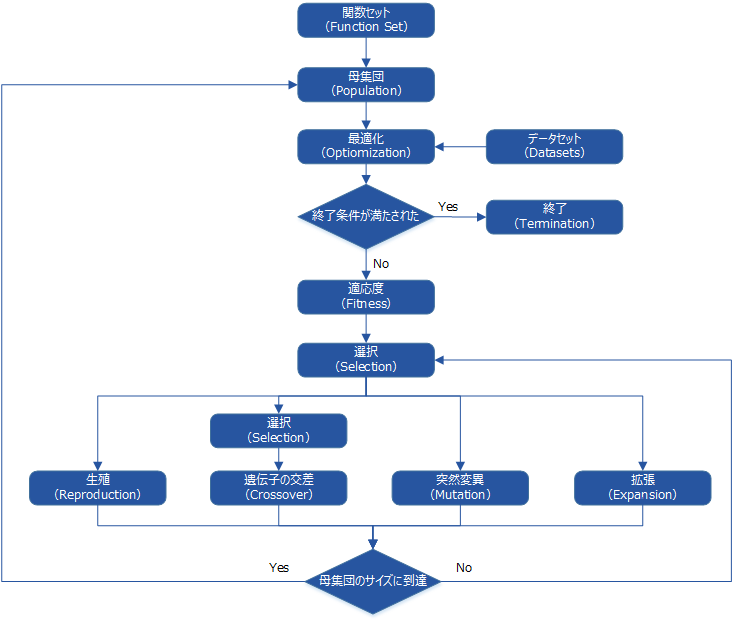
関数同定問題を実行するにあたり、ASCMO-MOCAは遺伝子プログラミングの修正版を採用しています。このアルゴリズムは、要求されたタスクの実行に特に適しています。上図に示されるアルゴリズムの主要なステップについて、以下に解説します。
アルゴリズムの過程で使用される関数式のセットを定義します。ASCMO-MOCAのこのステップでは、Selected Alphabet 領域のボタンで使用したい関数や演算子のタイプを選択します。
関数セットが定義された後に、モデルのセット(母集団)が確率論的に作成されます。このステップから、モデルはグラフで表されます。作成工程は、指定された母集団のサイズとグラフの規模によって制限されます。アルゴリズムの過程で、母集団は進化操作により進化します。アルゴリズムのメインループの1回の反復ステップが一世代に相当します。
|
注記 |
|---|
|
詳細な情報については、各フィールドのツールチップを参照してください。ツールチップをクリックすると、別ウィンドウで開くことができます。 |
"Symbolic Regression" ウィンドウ内の関連するコンフィギュレーションパラメータ(Optimization Configuration / Initial Configuration)は、以下のとおりです。
- Random Seed:乱数生成のシードとして使用される整数。アルゴリズム内のすべての確率論的ステップに影響します。この値を変更して、重要なケースのパフォーマンスを改善します。
- Population Size:各母集団に含まれるモデルの数。難解な問題については、一般的に「数千」の規模が適切に機能します。
- Population Creation Method(Initial Configuration):初期の母集団は、3種類のメソッドのうちのいずれかを用いて作成されます。未知の問題については一般的に "half and half" が適しています。
- half and half:母集団の半分は "full" メソッドで作成され、残りの半分は "grow" メソッドで作成されます。採用される最大深度値は、各グラフごとに、Population Init Depth Min と Population Init Depth Max の範囲内の均一分布から決定されます。
- full:各グラフは、すべてのブランチが Population Init Depth Max の深度を持つように作成されます。
- grow:各グラフは、1つ以上のブランチが Population Init Depth Max の深度を持つように作成されます。
- Population Init Depth Min:最小の初期深度。
- Population Init Depth Max:最大の初期深度。深度10のグラフは非常に巨大で複雑です。4前後の数値が適切です。
- Max Program Complexity(Optimization Configuration):初期時と進化中において、この「最大複雑度」よりも複雑なグラフは作成されません。グラフの複雑度は、グラフを構成するすべてのノードの複雑度の合計である整数です。ノードの複雑度は、ASCMO-MOCA内部で経験的に定義されます。関数同定問題の複雑性について明確な要求と経験があれば、このオプションを使用してアルゴリズムの実行を高速化できます。
-
Max Program Depth:初期時と進化中において、この最大深度よりも深いグラフは作成されません。
-
Max Program Size:初期時と進化中において、この最大サイズ(最大ノード数)より大きなグラフは作成されません。
関数同定問題を実行するには1つ以上のデータセットが必要です。
各グラフごとにローカル最適化が実行されます。この最適化の目的は、"Fitness Method" で指定されたメソッドを用いて得られる値を最小化することです。
関連するコンフィギュレーションパラメータ(Optimization Configuration)
- Optimizer Method
- Levenberg-Marquardt メソッド(LM)
- Trust-region-reflective メソッド
- Dogbox アルゴリズム
- Optimizer Iterations:ローカル最適化の最大反復回数
以下の条件が1つ以上満たされると、アルゴリズムは終了します。
- 母集団のモデルの1つについて、"Fitness Method" で指定されたメソッドにより得られた値が終了しきい値よりも小さい。
- 世代の最大数に達した。
関連するコンフィギュレーションパラメータ(Optimization Configuration)
- Termination Threshold:終了条件として使用されるしきい値。しきい値は正のダブル(倍精度)です。
- Number of Generations:世代の最大数
母集団内のモデルごとに適応度が計算されます。ここでは、以下の2つの部分の合計として、未加工の適合度が計算されます。
- "Fitness Method"(費用関数)として指定されたメソッドにより得られた値
- グラフの複雑さにペナルティを科すスカラ値
実際の適応度は、未加工の適応度を [0,1] の範囲の値に正規化することにより得られます。
関連するコンフィギュレーションパラメータ(Optimization Configuration)
- Fitness Method:以下の費用関数から選択します。
- rmse 2乗平均平方根誤差
- mse 2乗平均誤差
- abs 正規化絶対誤差(L^1-normの平均)
- Parsimony Coefficient:複雑性ペナルティの影響を重み付けするための係数。未知の問題については値1が妥当な出発点です。値を小さくするほど式は複雑になります。
グラフの構造的最適化は、母集団からグラフを選択することから始まります。選択は、前のステップで得られた適応性に基づき、以下のメソッドで行われます。
関連するコンフィギュレーションパラメータ(Optimization Configuration)
- Program Selection Method:
- tournament:指定されたトーナメントサイズのグラフが母集団からランダムに描画され、最大の適応度を持つグラフが選択されます。
> Tournament Size:トーナメントにより選択するプログラムの数。2つ以上の個体を選択すると、アルゴリズムの進行が非常に不安定になります。数が Population Size(母集団のサイズ)に収束する場合は、最も適応したプログラムの優位性が強制されます。出発点としては "Population Size" の約10%を選択するのが好ましいといえます。 - fitness-based:現在の母集団のすべてのグラフの適応度から確率分布が導出されます。この分布をサンプリングしてグラフを選択します。グラフの適応度が高いほど選択される可能性が高くなります。
- greedy overselection:母集団が適応度の高いグループと低いグループに分割されます。両グループに対して適応度ベースの選択が行われます。適応度の高いグループを採用する確率は Probability Top で決定されます。それ以外の場合は適応度の低いグループが選択されます。
> Fraction Top:適応度の高いグループのサイズを決定するための、母集団に対する割合です。適応度が最も高いグラフがグループに含まれることになります。
> Probability Top:適応度ベースの選択において適応度の高いグループが使用される確率です。 - multi tournament:tournamentと似ています。確率を選択できますが、適応度の代わりに適応度/複雑度が基準として使用されます。このオプションは、遺伝的プログラミングのような勾配のない手法にのみ与えられる、複数の基準による最適化の可能性を示しています。
> Tournament Size:トーナメントにより選択するプログラムの数。2つ以上の個体を選択すると、アルゴリズムの進行が非常に不安定になります。数が Population Size(母集団のサイズ)に収束する場合は、最も適応したプログラムの優位性が強制されます。出発点としては "Population Size" の約10%を選択するのが好ましいといえます。
> Probability Fitness:適応度の代わりに適応度/複雑度を使用する確率
- tournament:指定されたトーナメントサイズのグラフが母集団からランダムに描画され、最大の適応度を持つグラフが選択されます。
進化ステップは、生殖、拡張、突然変異、遺伝子交叉、といったグラフ変更操作で構成されます。これは実際の構造的最適化ステップであり、前のステップで選択したグラフに依存します。各手法の確率に応じて、それらがこのグラフにどのように適用されるかが決定されます。
関連するコンフィギュレーションパラメータ(Evolution Probabilities)
以下のオプションで、4つの操作を実行する確率を定義します。確率の合計が100になるようにしてください。
- Crossover:80~90の範囲が適しています。
- Reproduction:この操作は、適応度の高いグラフがそのまま変更されずに次世代に引き継がれるようにするものです。
- Expansion
- Mutation
Reproduction(生殖)
「グラフの生殖」は、次世代の母集団にグラフをそのまま引き継ぐことを意味します。
Expansion(拡張)
「グラフの拡張」は以下のように行われます。
- グラフの終端ノードをランダムに選択します。
- 深度2の新しいランダムグラフを作成します。
- 終端ノードを新しいグラフに置き換えます。
拡張されたグラフの方が元のグラフより適応度が高い場合は、拡張されたグラフが次の世代に引き継がれます。そうでない場合は元のグラフがそのまま引き継がれます。
Mutation(突然変異)
「グラフの突然変異」は、グラフ内でランダムに選択されたノードに適用される3つの操作により実行されます。
- New Tree:選択されているノードとそのすべてのサブノードを、新しく作成されたグラフ(最大深度3)に置き換えます。
- Hoist:グラフの正当性は保持したまま、選択されているノードを削除します。この操作は、グラフの膨張を防ぐのに役立ちます。
- Point:選択されているノードを、同じ入力数のランダムノードに置き換えます。
どのメソッドをどのように適用するかは、個々の確率で決まります。3つの確率の合計が100になるようにしてください。
関連するコンフィギュレーションパラメータ(Mutuation Probabilities)
- New Tree:New Tree処理を実行する確率
- Hoist:Hoist Mutation処理を実行する確率
- Point:Point Mutation処理を実行する確率
Crossover(遺伝子の交叉)
遺伝子交叉の操作は基本的に、2つのグラフを再結合してより適応度の高いグラフを見つけることです。操作は、次の手順で実行されます。
-
前のステップで選択したグラフを「ターゲットグラフ」とします。
-
第2のグラフを選択します。このグラフは、"Program Selection" で指定され、ソースグラフとして定義されたものです。
-
両グラフにおいて、1つのノードとそのすべてのサブノードを、交換するブランチとしてそれぞれランダムに選択します。
-
ターゲットグラフ内のブランチをソースグラフのブランチに置き換えます。
この操作の結果であるグラフが、次世代の母集団に引き継がれます。
進化の各操作は、次世代の母集団が Population Size で定義された数のメンバーを持つまで適用されます。