Model Prediction with Convolutional Neural Network (CNN)
ASCMO-DYNAMIC offers the possibility to use Convolutional Neural Networks (CNNs) for transient modeling. As for RNNs, the open source machine learning platform Tensorflow is the underlying basis.
CNNs have long been the state-of-the-art approach for solving image-based tasks. Recently, CNNs have become increasingly popular for time series modeling tasks. Instead of using 2D convolutions as in the image use case, 1D convolutions are used in the time series use case.
The CNNs in ASCMO-DYNAMIC are sequence-to-sequence models. This means that for each new input xt at time step t, exactly one output value yt is calculated.
By using the so-called causal padding (see Fig. 10) it is ensured that there is no information leakage from the future to the past, i.e. for the calculation of an output value y only the current input value is used together with past input values.
Each CNN layer consists of n filters with kernel size k (see Fig. 10), where n and k can be set by the user for each layer separately. The number of network parameters and thus the computational power of the network is increased by increasing the number of layers or by increasing n and/or k. The computational flow of a CNN is shown schematically in Fig. 10.
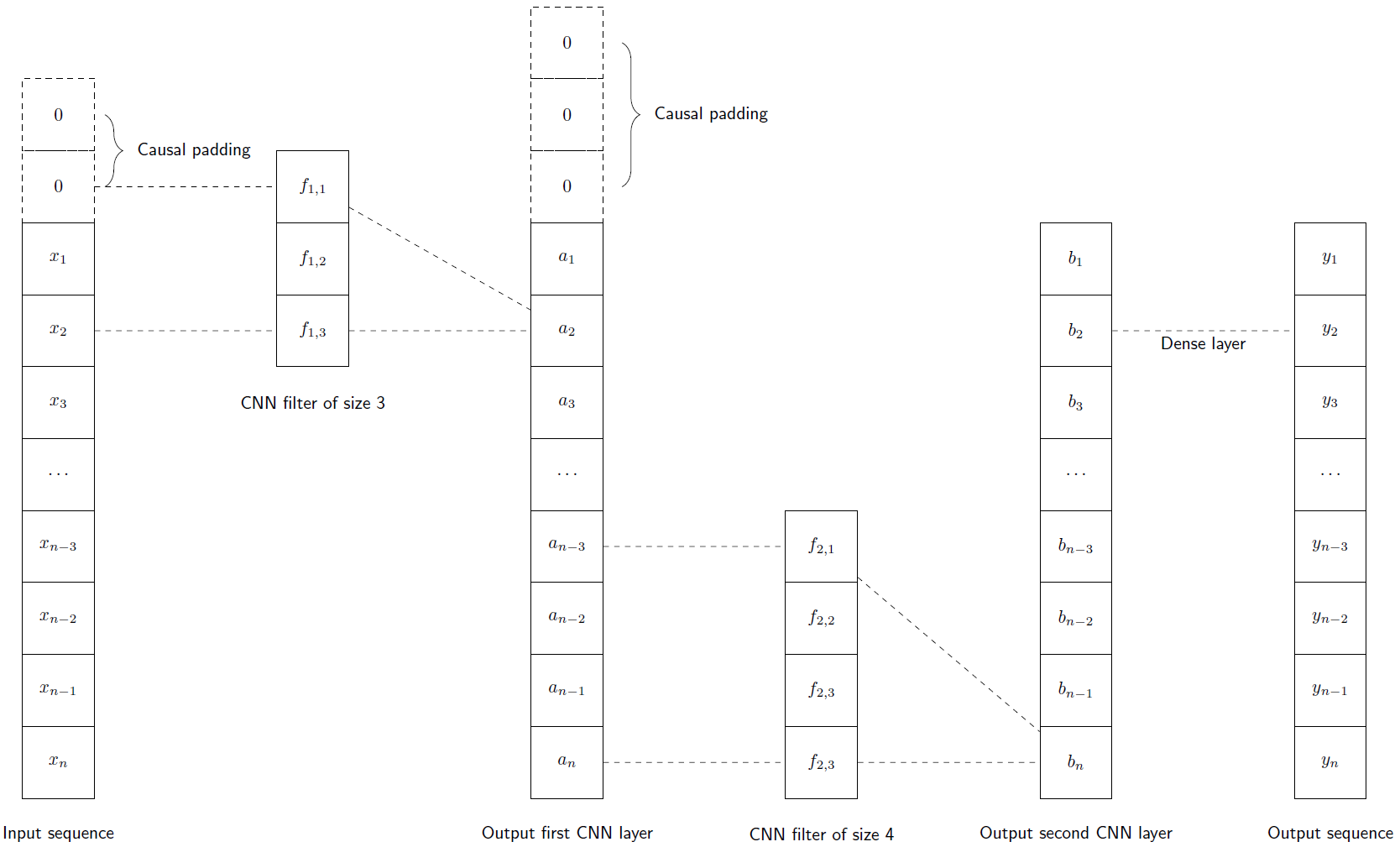
Fig. 10 shows a schematic representation of a 1D convolutional network consisting of two convolutional layers followed by a dense layer. For simplicity, the input sequence x = (x1,....., xn), where the index represents the time step, has only one feature, and both convolutional layers have only one filter each. In order not to take future time steps into account when calculating an output value, the input sequence and the output sequence of the first layer use causal padding (filling with zeros at the beginning).
For the calculation of the ith output value yi, the filter of the first layer is applied to (xi, xi-1, xi-2), resulting in ai. The filter of size four of the second layer is then applied to the sequence (ai, ai-1, ai-2, ai-3) (note that all values have been calculated in previous time steps), resulting in bi. The final dense layer converts bi to the output value yi.
Each CNN model has a fixed receptive field that determines how far into the past the model can look. In other words, any information from the input sequence that is not covered by the receptive field will be ignored in the calculation of the corresponding output. The length of the receptive field can be influenced by the number of layers, the kernel size of each layer, and the dilation rate of each layer (see Fig. 11 for a schematic representation of these effects).
CNNs that use causal padding and dilation are often referred to as Temporal Convolutional Networks (TCNs). ASCMO-DYNAMIC provides a special type of layer called Temporal Convolutional Network (TCN), which is particularly suited to modelling temporal sequences. It consists of two convolutional layers with the same number of filters, size and dilation rate. For a network with multiple TCN layers, the dilation rate increases exponentially with each layer to achieve the largest possible receptive field with the fewest layers and parameters.
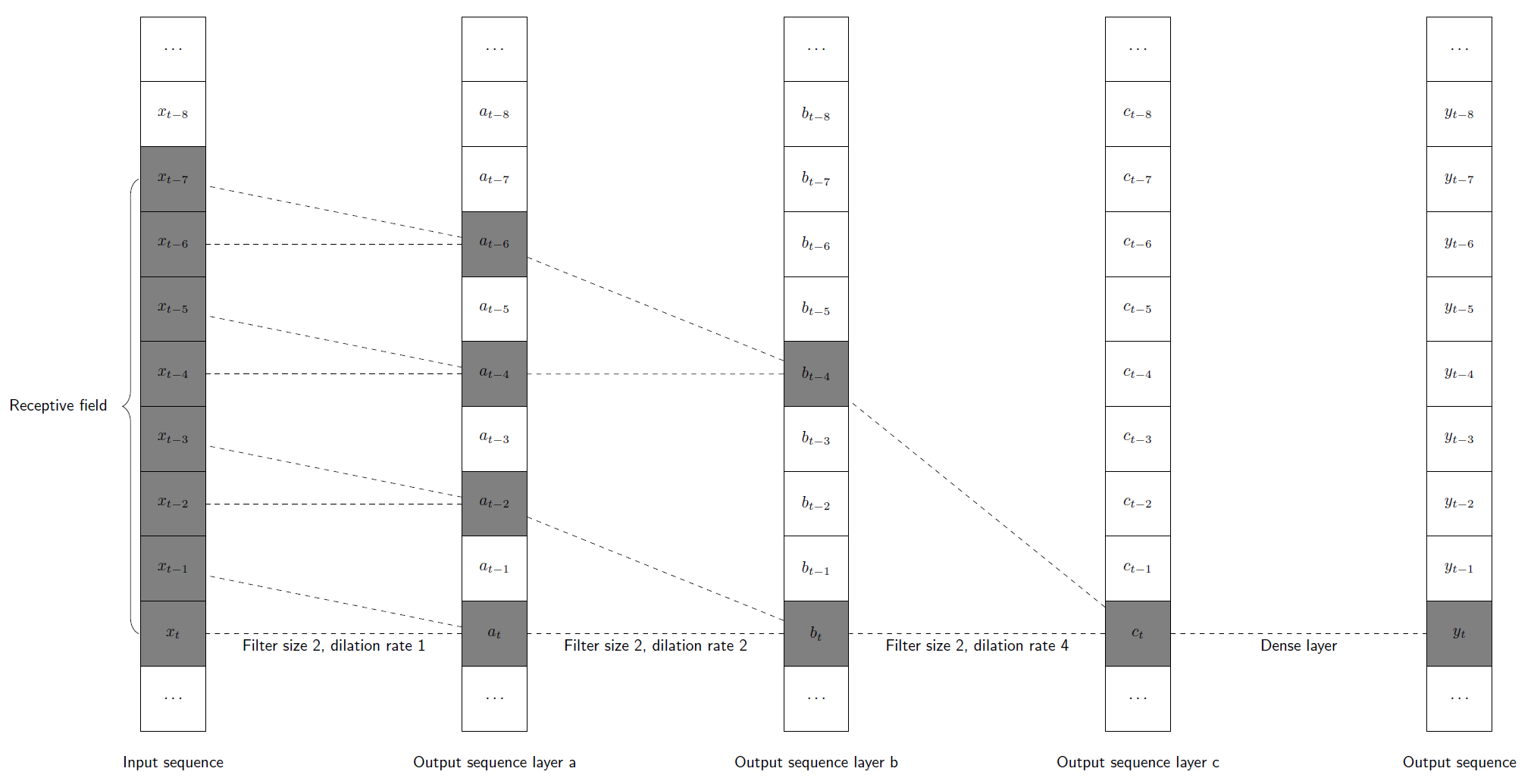
Fig. 11: CNN scheme using dilation
Fig. 11 shows a schematic representation of a 1D convolutional network using dilation. The kernel size (2 for all three CNN layers in Fig. 11) and the dilation rate can be used to increase the receptive field of a convolutional network. In Fig. 11, the first layer uses a dilation rate of 20 = 1, the second layer uses a dilation rate of 21 = 2, and the third layer uses a dilation rate of 22 = 4. Note that with these settings, exactly 8 values of the input sequence are used to compute an output value yt (xt-7,....., xt), and we say that the receptive field has length 8.
See also